Fine-Tune Wav2Vec2 for English ASR in Hugging Face with 🤗 Transformers
About this article
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
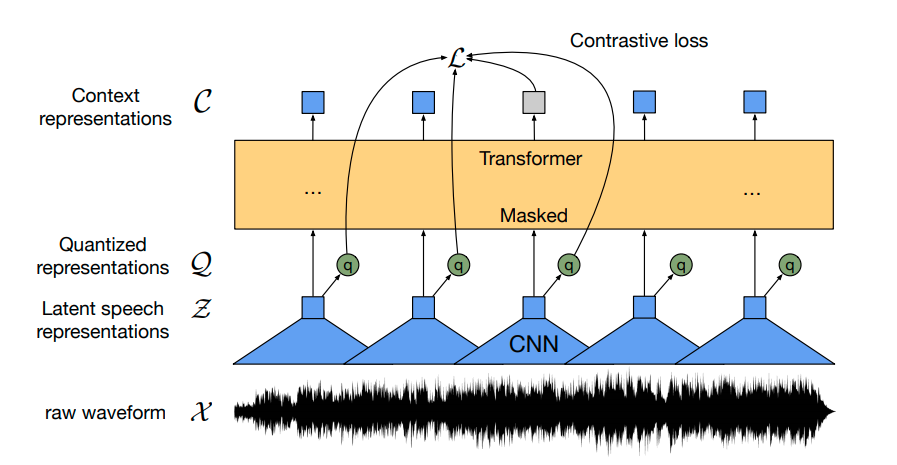
Back to Articles Fine-Tune Wav2Vec2 for English ASR with 🤗 Transformers Published March 12, 2021 Update on GitHub Upvote 43 +37 Patrick von Platen patrickvonplaten Follow Wav2Vec2 is a pretrained model for Automatic Speech Recognition (ASR) and was released in September 2020 by Alexei Baevski, Michael Auli, and Alex Conneau. Using a novel contrastive pretraining objective, Wav2Vec2 learns powerful speech representations from more than 50.000 hours of unlabeled speech. Similar, to BERT's masked language modeling, the model learns contextualized speech representations by randomly masking feature vectors before passing them to a transformer network. For the first time, it has been shown that pretraining, followed by fine-tuning on very little labeled speech data achieves competitive results to state-of-the-art ASR systems. Using as little as 10 minutes of labeled data, Wav2Vec2 yields a word error rate (WER) of less than 5% on the clean test set of LibriSpeech - cf. with Table 9 of the paper. In this notebook, we will give an in-detail explanation of how Wav2Vec2's pretrained checkpoints can be fine-tuned on any English ASR dataset. Note that in this notebook, we will fine-tune Wav2Vec2 without making use of a language model. It is much simpler to use Wav2Vec2 without a language model as an end-to-end ASR system and it has been shown that a standalone Wav2Vec2 acoustic model achieves impressive results. For demonstration purposes, we fine-tune the "base"-sized pretrained chec...
