Fit More and Train Faster With ZeRO via DeepSpeed and FairScale
About this article
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
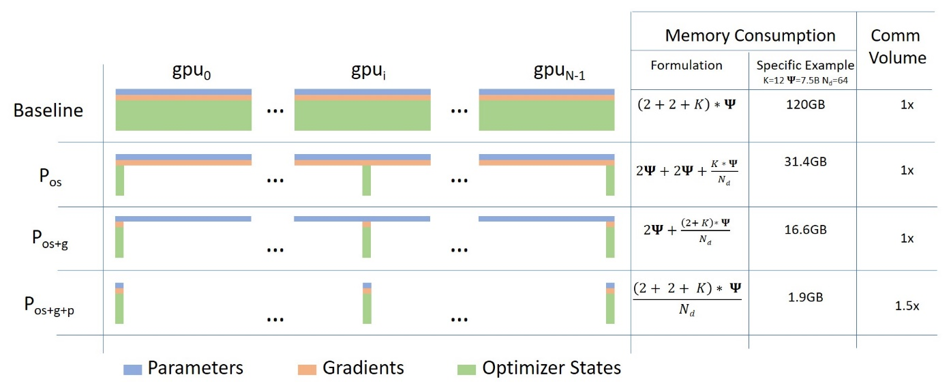
Back to Articles Fit More and Train Faster With ZeRO via DeepSpeed and FairScale Published January 19, 2021 Update on GitHub Upvote 5 Stas Bekman stas Follow guest A guest blog post by Hugging Face fellow Stas Bekman As recent Machine Learning models have been growing much faster than the amount of GPU memory added to newly released cards, many users are unable to train or even just load some of those huge models onto their hardware. While there is an ongoing effort to distill some of those huge models to be of a more manageable size -- that effort isn't producing models small enough soon enough. In the fall of 2019 Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase and Yuxiong He published a paper: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, which contains a plethora of ingenious new ideas on how one could make their hardware do much more than what it was thought possible before. A short time later DeepSpeed has been released and it gave to the world the open source implementation of most of the ideas in that paper (a few ideas are still in works) and in parallel a team from Facebook released FairScale which also implemented some of the core ideas from the ZeRO paper. If you use the Hugging Face Trainer, as of transformers v4.2.0 you have the experimental support for DeepSpeed's and FairScale's ZeRO features. The new --sharded_ddp and --deepspeed command line Trainer arguments provide FairScale and DeepSpeed integration respectively. Here is the fu...
