Hugging Face Reads, Feb. 2021 - Long-range Transformers
About this article
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
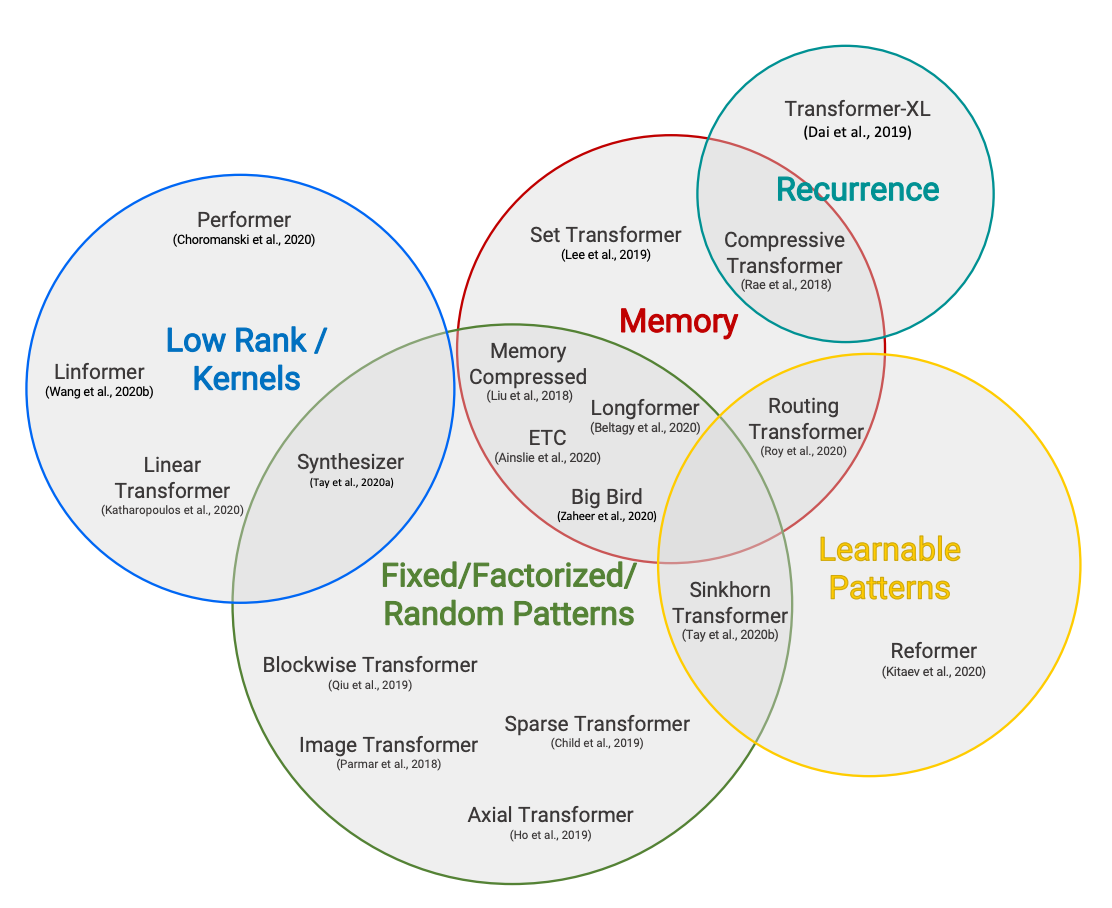
Back to Articles Hugging Face Reads, Feb. 2021 - Long-range Transformers Published March 9, 2021 Update on GitHub Upvote 3 Victor Sanh VictorSanh Follow Efficient Transformers taxonomy from Efficient Transformers: a Survey by Tay et al. Co-written by Teven Le Scao, Patrick Von Platen, Suraj Patil, Yacine Jernite and Victor Sanh. Each month, we will choose a topic to focus on, reading a set of four papers recently published on the subject. We will then write a short blog post summarizing their findings and the common trends between them, and questions we had for follow-up work after reading them. The first topic for January 2021 was Sparsity and Pruning, in February 2021 we addressed Long-Range Attention in Transformers. Introduction After the rise of large transformer models in 2018 and 2019, two trends have quickly emerged to bring their compute requirements down. First, conditional computation, quantization, distillation, and pruning have unlocked inference of large models in compute-constrained environments; we’ve already touched upon this in part in our last reading group post. The research community then moved to reduce the cost of pre-training. In particular, one issue has been at the center of the efforts: the quadratic cost in memory and time of transformer models with regard to the sequence length. In order to allow efficient training of very large models, 2020 saw an onslaught of papers to address that bottleneck and scale transformers beyond the usual 512- or 10...
