Retrieval Augmented Generation with Huggingface Transformers and Ray
About this article
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
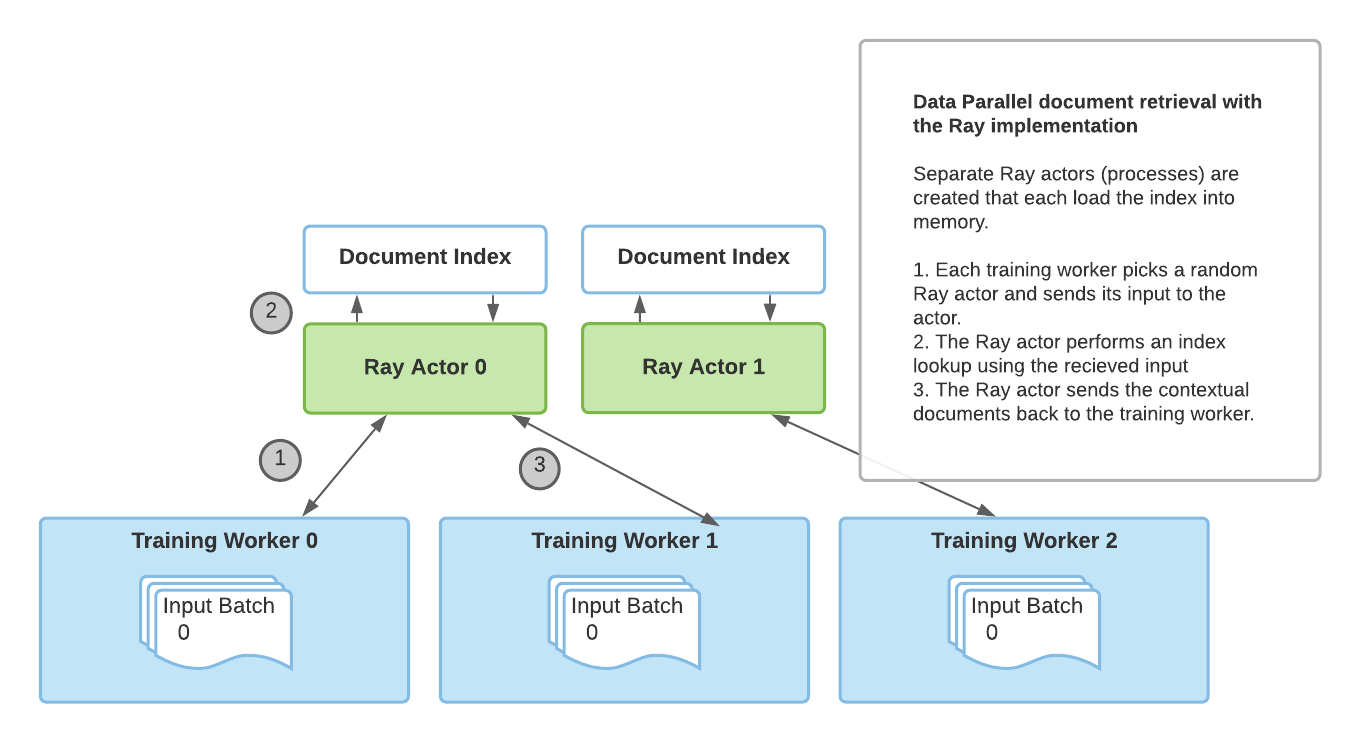
Back to Articles Retrieval Augmented Generation with Huggingface Transformers and Ray Published February 10, 2021 Update on GitHub Upvote 6 system system Follow A guest blog post by Amog Kamsetty from the Anyscale team Huggingface Transformers recently added the Retrieval Augmented Generation (RAG) model, a new NLP architecture that leverages external documents (like Wikipedia) to augment its knowledge and achieve state of the art results on knowledge-intensive tasks. In this blog post, we introduce the integration of Ray, a library for building scalable applications, into the RAG contextual document retrieval mechanism. This speeds up retrieval calls by 2x and improves the scalability of RAG distributed fine-tuning. What is Retrieval Augmented Generation (RAG)? An overview of RAG. The model retrieves contextual documents from an external dataset as part of its execution. These contextual documents are used in conjunction with the original input to produce an output. The GIF is taken from Facebook's original blog post. Recently, Huggingface partnered with Facebook AI to introduce the RAG model as part of its Transformers library. RAG acts just like any other seq2seq model. However, RAG has an intermediate component that retrieves contextual documents from an external knowledge base (like a Wikipedia text corpus). These documents are then used in conjunction with the input sequence and passed into the underlying seq2seq generator. This information retrieval step allows RAG ...
