Speculative Decoding for 2x Faster Whisper Inference
About this article
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
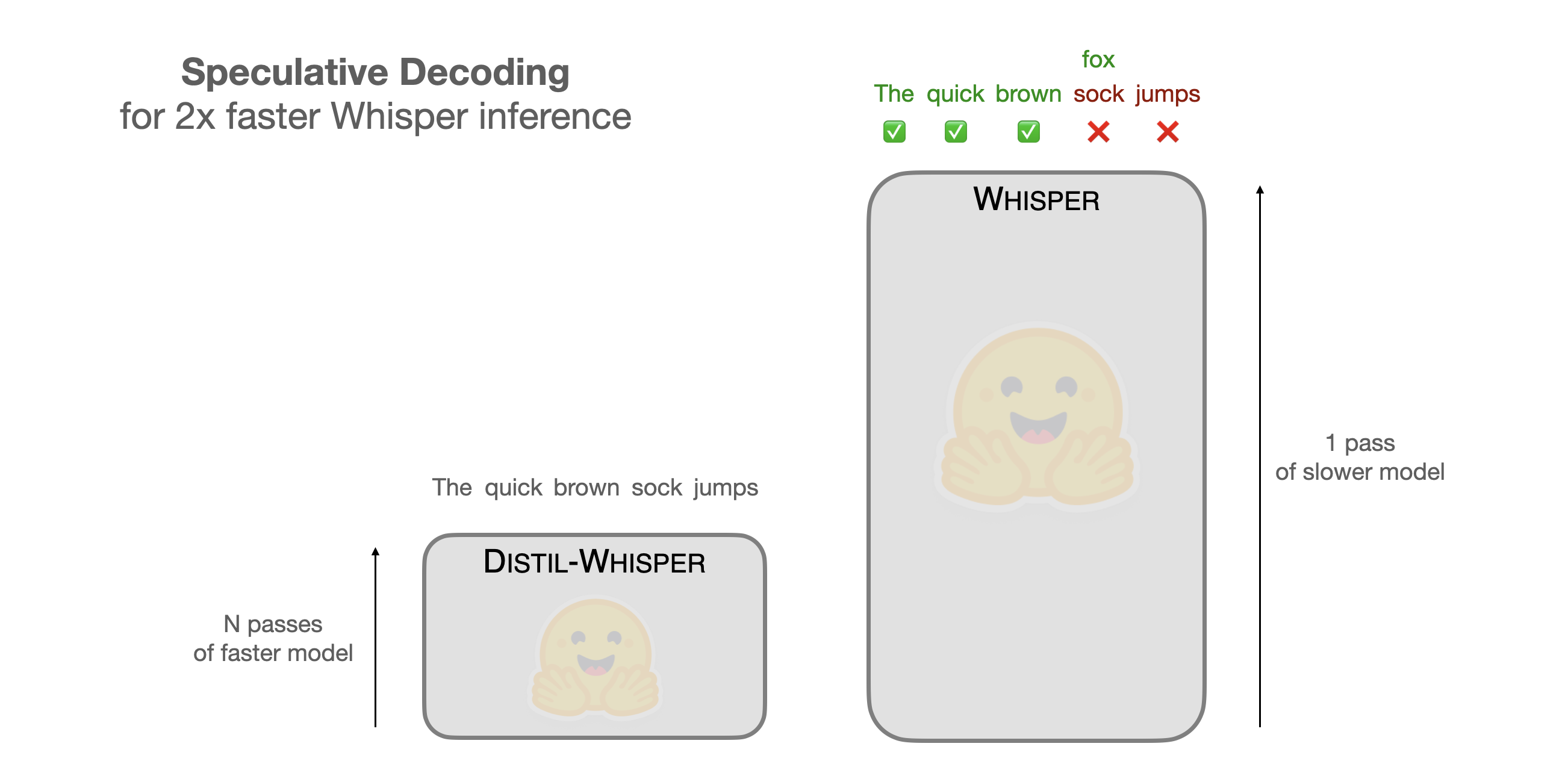
Back to Articles Speculative Decoding for 2x Faster Whisper Inference Published December 20, 2023 Update on GitHub Upvote 30 +24 Sanchit Gandhi sanchit-gandhi Follow Open AI's Whisper is a general purpose speech transcription model that achieves state-of-the-art results across a range of different benchmarks and audio conditions. The latest large-v3 model tops the OpenASR Leaderboard, ranking as the best open-source speech transcription model for English. The model also demonstrates strong multilingual performance, achieving less than 30% word error rate (WER) on 42 of the 58 languages tested in the Common Voice 15 dataset. While the transcription accuracy is exceptional, the inference time is very slow. A 1 hour audio clip takes upwards of 6 minutes to transcribe on a 16GB T4 GPU, even after leveraging inference optimisations like flash attention, half-precision, and chunking. In this blog post, we demonstrate how Speculative Decoding can be employed to reduce the inference time of Whisper by a factor of 2, while mathematically ensuring exactly the same outputs are achieved from the model. As a result, this method provides a perfect drop-in replacement for existing Whisper pipelines, since it provides free 2x speed-up while maintaining the same accuracy. For a more streamlined version of the blog post with fewer explanations but all the code, see the accompanying Google Colab. Speculative Decoding Speculative Decoding was proposed in Fast Inference from Transformers via S...
