Understanding BigBird's Block Sparse Attention
About this article
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
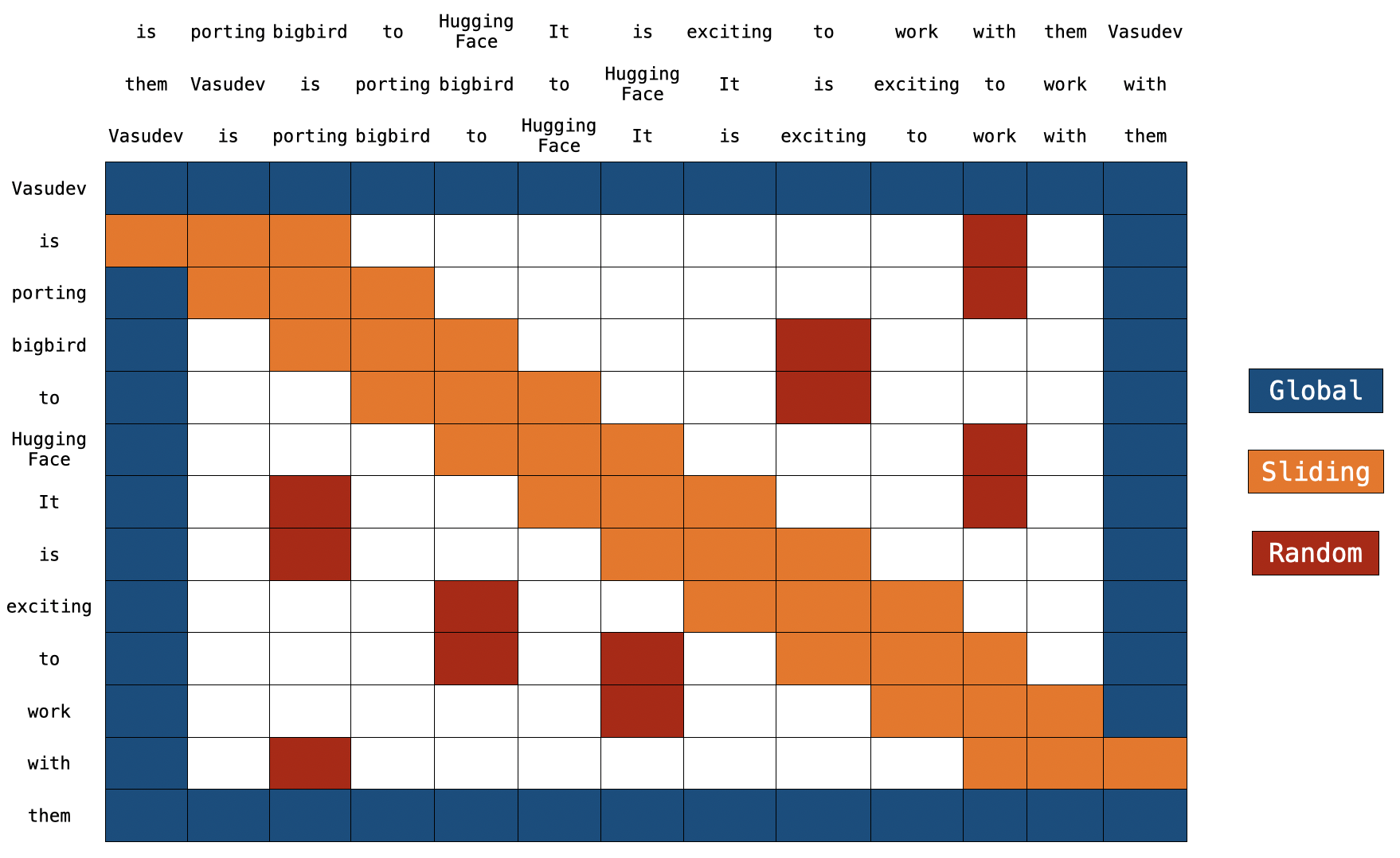
Back to Articles Understanding BigBird's Block Sparse Attention Published March 31, 2021 Update on GitHub Upvote 8 +2 Vasudev Gupta vasudevgupta Follow Introduction Transformer-based models have shown to be very useful for many NLP tasks. However, a major limitation of transformers-based models is its O(n2)O(n^2)O(n2) time & memory complexity (where nnn is sequence length). Hence, it's computationally very expensive to apply transformer-based models on long sequences n>512n > 512n>512. Several recent papers, e.g. Longformer, Performer, Reformer, Clustered attention try to remedy this problem by approximating the full attention matrix. You can checkout 🤗's recent blog post in case you are unfamiliar with these models. BigBird (introduced in paper) is one of such recent models to address this issue. BigBird relies on block sparse attention instead of normal attention (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a much lower computational cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts. BigBird RoBERTa-like model is now available in 🤗Transformers. The goal of this post is to give the reader an in-depth understanding of big bird implementation & ease one's life in using BigBird with 🤗Transformers. But, before going into more depth, it is important to remember that the BigBird's attention is an approximation of BERT's full attentio...
